
调用超时问题排查思路
# 前言
回顾这几年处理过一些接口超时问题,总结下超时问题发生的阶段和排查思路。主要分为后端服务内部调用和用户通过客户端调用两方面导致的超时。
# 服务内部调用
# 引发耗时的场景
- 程序发起请求,等待cpu调度
- 解析域名
- 建立链接(三次握手,ssl)
- 网关转发耗时
- mesh耗时
- 后端应用链接队列
- 后端处理请求耗时
- 分为调用其他服务接口
- 后端自身的计算或IO耗时
- 网络问题
# 1. 程序发起请求,等待cpu调度
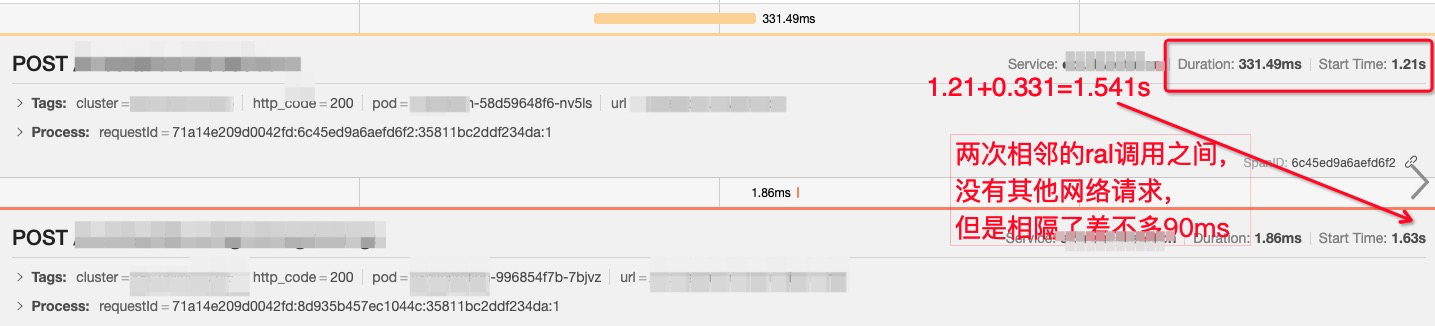
线上案例:单台node节点调度过多的容器,产生几万个进程,cpu调度能力明显变慢,node cpu使用率飙升,可以从链路追踪定位原因,先看一张耗时变大的链路追踪和一张正常状态的链路追踪图
两次相邻请求间隔耗时增大至90ms:
node负载正常时的请求耗时间隔3ms
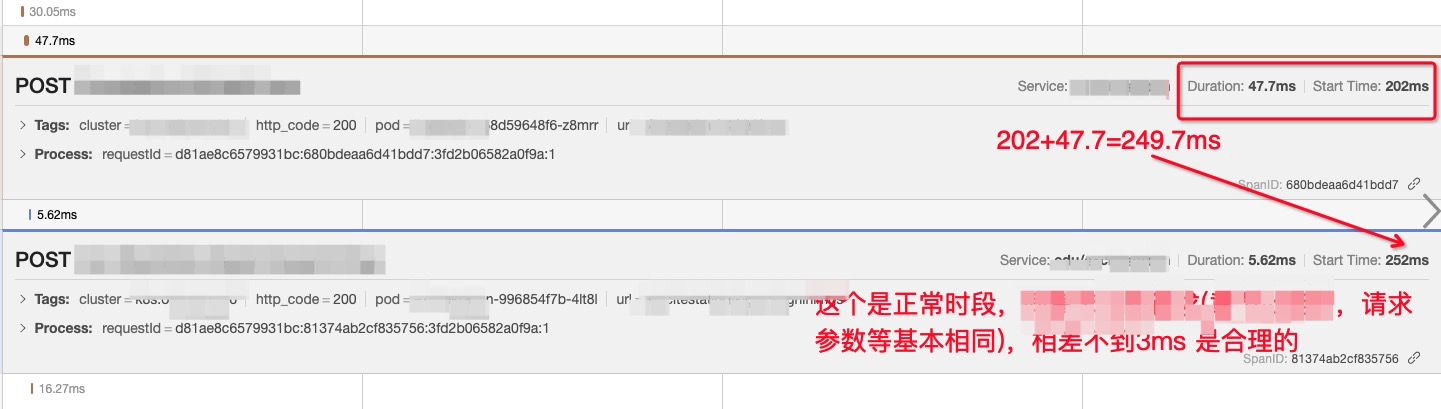
通过这两张图可以得出猜想:两个请求间隔的耗时增大,是等待cpu调度的时间,
验证猜想:查看pod负载并不高,怀疑是node负载高,联系相关负责人查看,确定是机器负载太高。
# 2. 解析域名
线上案例:线上服务器访问某个域名5s超时,从报错来看不像是服务端超时,在nslookup域名时时耗时大,问题简单明了,链接某个dns服务器耗时增大
查询耗时:
time nslookup baidu.com
看下real time即可。
# 3. 建立链接(三次握手,ssl)
线上案例:20220831某工区报障,客户端到服务端部分请求超时,一时间没有找到异同点,但可以确定建连超时,此时需要确定是在哪一阶段出现了超时。
curl -X GET -w ``"\ntime_namelookup:%{time_namelookup}\ntime_connect: %{time_connect}\ntime_appconnect: %{time_appconnect}\ntime_redirect: %{time_redirect}\ntime_pretransfer: %{time_pretransfer}\ntime_starttransfer: %{time_starttransfer}\ntime_total: %{time_total}\n"` `http:``//url
以上代码可以打印发起请求的各阶段耗时,本次是ssl阶段超时,抓包看是没有收到回包。
# 4. 7层nginx转发
根据历史日志看正常情况下网关纯转发耗时都是小于1ms,在排查问题时有时需要自证清白,可通过nginx request_time-upstream_response_time 得到转发耗时。
# 5. mesh耗时
同上,不过service mesh不止转发,还有限流等其他功能,接入的功能越多引发变更的点就越多,也容易出问题。
# 6. 后端应用链接队列
当应用程序tcp链接队列打满时,表示后端服务过载,比较常见的是 Connection reset” 错误,导致这种错误的原因就是服务端因为某种原因关闭了 Connection,而客户端仍然在读写数据,此时服务器会返回复位标志 “RST”,如果任何一方发出RST,这意味着整个连接被中止,TCP栈可以丢弃任何没有被任何应用程序发送或接收的队列数据。现象是服务端没收到这个请求,上游服务说调用超时了。
常用的几个排查命令:
#查看TCP半连接队列溢出:
netstat -s | grep LISTEN
# 查看TCPaccept队列溢出:
netstat -s | grep overflow
2
3
4

参数说明:
- Recv-Q:全连接当前长度
- Send-Q:如果连接不是在建立状态,则是当前全连接最大队列长度
如9523端口,队列长度为50,已使用0个。
全连接队列的大小为 backlog 和 somaxconn 的最小值,那么来看下 somaxconn 的取值
sysctl -a |grep net.core.somaxconn
net.core.somaxconn = 65535 #65535
2
此时可以告知研发调大backlog的值,之前维护的java服务有这个问题。而php服务则是cgi队列溢出。
# 7. 后端处理请求耗时
后端处理的逻辑可能有调用其他接口、本身做一些计算类操作、IO类操作,而链路追踪可以追到的是发起请求的调用,对于程序本身计算或IO的操作却没法展示的那么详细,所以需要结合代码以及链路追踪看具体耗时在哪。必要时可要求研发对于某些疑似耗时逻辑增加日志记录。
# 8. 网络问题
内网网络问题,很少出现高耗时,但也是最被容易甩锅的一个(实在不得不吐槽一句线上无法做到每台机器和其他所有机器做一个网络监控,非常容易被一些”年轻人“甩锅),既然线上无法针对所有机器进行双向监控,查询问题一般依赖服务日志,比如odp(内部php框架)日志有发起请求时间,也有收到请求时间,甚至建联耗时 读、写耗时,对于排查问题很方便,反观go服务框架层面并没有这么详细的耗时日志打印。所以mesh层一定程度上能够帮助排查两台机器间是否有网络问题。
# 客户端调用
# 核心链路和设备
- 用户设备
- 用户局域网
- local dns
- 运营商/骨干网
- 云厂商/云产品
# 1. 用户设备
在线直播场景的付费课程和用户联系紧密,一有问题就会很快反馈到辅导老师进而转发至SRE侧。
常见的问题比如设备卡顿,设备装了一些vpn或杀毒软件倒是网络不通。用户设备问题千奇百怪,有很多工单报上来,再回访用户就已经好了,大多是用户自身问题,对我们来说无法登录测试也很难排查。(这点得吐槽客户端,端的切换能力略差,一键诊断工具得向大厂对齐)
# 2. 用户局域网
小运营商网速慢、网络质量差,比如光电、长城、宽带通等不知名三四级承包商
用户开vpn代理没有绕过大陆ip
路由器质量差、信号强度、信道拥堵等等
对于直播场景来说,现在都是RTC低延迟直播,对时延要求很高,并且UDP协议弱网本身就会影响质量,不是头条,抖音能用就说明网络没问题,抖音可以提前缓冲视频,断网了也能看几个,而上课场景都是实时的,网络需要保持稳定,别的设备下载视频占用带宽比较大可能都会影响直播效果。而且带货直播或游戏直播通常是RTMP直播,有一定差距。
# 3. local dns
劫持
响应慢
返回的ip不是就近或者不是同一个运营商
如果设备可以远程,nslookup下基本就能看出来,用上面的curl打印各阶段耗时也可以,httpdns可以缓解这个问题(不能保证端都能走httpdns)
# 4. 运营商/骨干网
这一个阶段是最难排查,运营商有很多自己的缓存服务,即使解析ip对,也不一定就能到达服务,也可能命中他们缓存,并且时延也是不能保证的。计算耗时可以用LB收到请求的时间-客户端发请求的时间来计算,但有一个坑,客户端时间不一定准,我们多次见过发请求的时间在收到请求时间之后,当然请求是有唯一id的,不会出错。
# 5. 云厂商/云产品
云厂商的故障通过目前添加的监控也基本能发现,并且公网访问的监控腾讯云已经做的比较好,可以报出来。至于云产品的问题大多需要抓包来找证据,通常也是网络传输问题。(腾讯云推送的地域故障通常比我们发现的慢几分钟)
# 总结/思考
不管对于什么样的网络问题,只要能复现都能解决,不能复现则会麻烦一些。
解决问题最重要的是信息的收集,服务端因为能登录还能收集到信息,客户端大部分黑盒(还是看端的能力,能否上报信息,但网络有问题时大概率当时上传失败),排查问题几乎靠经验分析,并且端上对于排查问题有用的日志极少,最终还是需要远程登录一个客户端进行网络测试、信息收集、数据分析、客户端多域名测试的方案。
服务端思路较为清晰,但容器化后带给我们更大的排查难度,很多链路是黑盒,并且没有日志,只能靠抓包,链路追踪并不能覆盖所有环节,有待产出更好的排查方案。
所有问题都需要业务部门的反馈,这个时候需要辨别信息真伪,从经验看,能够给出正确信息的不足三成,一定需要专业知识来看出背后真实的问题,否则会被绕远路。
# 附
分享一个比较常用的问题排查方法, 常见linux问题排查方法 (opens new window)
