
玩转AIGC原理+实战🔥
AIGC(Artificial Intelligence Generated Content)是人工智能生成内容的意思。它是一种利用人工智能技术创造生成内容的技术,其中包括文本、图像、音频、视频等多种形式。AIGC技术融合了深度学习、自然语言处理、计算机视觉等多个领域的发展,能够模拟人类创作过程并自动生成新的内容。AIGC的应用范围广泛,包括但不限于新闻媒体、教育、游戏、艺术、娱乐等多个领域。随着人工智能技术的不断发展,AIGC将会在更多的领域得到应用。
# 大模型
# 大模型是什么
以众所周知的chatGPT为例,GPT的全称,是Generative Pre-Trained Transformer(生成式预训练转换器)是一种基于互联网的、可用数据来训练的、文本生成的深度学习模型。
GPT是AIGC的一个种类。
在ChatGPT之前,被公众关注的AI模型是用于单一任务的,比如全球所知的“阿尔法狗”(AlphaGo)可以基于全球围棋棋谱的计算,打赢所有的人类围棋大师。谷歌进一步开发的“AlphaZero”在围棋、国际象棋和日本象棋等项目上,都是所向无敌。
这种专注于某个具体任务建立的AI数据模型,叫“小模型”。
ChatGPT与这种“小模型”不同,GPT大模型更像人类的大脑。它兼具“大规模”和“预训练”两种属性,可以在海量通用数据上进行预先训练,能大幅提升AI的泛化性、通用性、实用性。
大模型是指具有大量参数和计算资源的机器学习模型。这些模型通常在训练过程中需要大量的数据和计算能力,并且具有数百万到数十亿个参数(通常在十亿个以上)。大模型的设计目的是为了提高模型的表示能力和性能,在处理复杂任务时能够更好地捕捉数据中的模式和规律。
大模型的优势在于能够学习更多的特征和模式,从而提高对输入数据的理解和处理能力。它们可以更准确地进行预测和分类,产生更自然的语言生成结果,或者在复杂的决策问题上做出更明智的选择。然而,大模型也存在一些挑战,包括训练时间长、计算资源要求高以及部署和维护的复杂性等。
大模型应用的领域:
自然语言处理(NaturalLanguage Processing,NLP):大模型在NLP领域中具有显著的影响力。例如,GPT-3模型能够生成自然语言文本、进行对话和回答问题,BERT模型在语义理解和文本分类任务上表现出色。
计算机视觉(ComputerVision):大模型在图像识别 (opens new window)、目标检测、图像分割等计算机视觉任务中有重要应用。例如,深度卷积神经网络(CNN)的大型变体在图像分类竞赛中取得了卓越成绩。
语音识别(SpeechRecognition):大模型在语音识别领域有广泛应用,帮助改善语音转文字的准确性和自然度。例如,基于循环神经网络(RNN)的大模型在语音识别系统中起着重要作用。
推荐系统(RecommendationSystems):大模型在个性化推荐系统中扮演着重要角色。它们可以根据用户的历史行为和兴趣,提供个性化的推荐结果,帮助用户发现感兴趣的内容。
强化学习(ReinforcementLearning):大模型在强化学习领域也得到广泛应用。例如,AlphaGo和AlphaZero就是基于大模型和深度强化学习技术开发的,取得了在围棋和其他棋类游戏中超越人类水平的成果。
除了以上领域,大模型还在金融预测、医学影像分析、自动驾驶、机器人控制等多个领域有所应用。大模型的强大表示能力使其能够处理复杂的数据和任务,并取得令人瞩目的性能。
# 大模型的过人之处
# 涌现
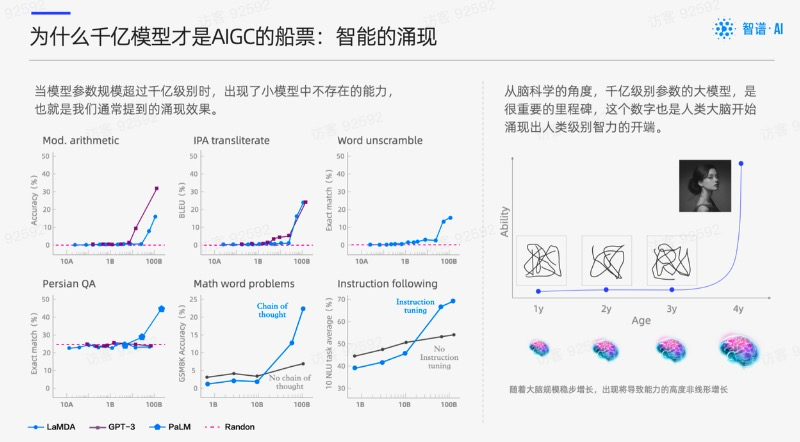
在大型语言模型(LLM)中,涌现能力(Emergent Abilities)是指模型具有从原始训练数据中自动学习并发现新的、更高层次的特征和模式的能力。就中文释义而言,涌现能力也指大语言模型涌现出来的新能力。这有点类似于去超市遇到买二赠一,赠品的质量居然还出乎意料。
在语言模型发展的早期,通过在更多数据上训练更大的模型,可获得近似连续的精确度提升。(可称为缩放定律/Scaling Laws)到了2015年左右,随着深度学习技术的发展和语料库的增大,模型达到一定的临界规模后,NLP开发者们发现,大语言模型(包括GPT-3、GLaM、LaMDA和Megatron-Turing NLG等)开始表现出一些开发者最开始未能预测的、更复杂的能力和特性,这些新能力和新特性被认为是涌现能力的体现。
涌现能力的另一个重要表现是模型的泛化能力。在没有专门训练过的情况,GPT-4也可以泛化到新的、未知的多模态数据样本上。这种泛化能力取决于模型的结构和训练过程,以及数据的数量和多样性。如果模型具有足够的复杂性和泛化能力,就可以从原始数据中发现新的、未知的特征和模式。
当然,G大模型涌现出的新能力可能仍有局限性,例如:模型可能产生错误的回答,对某些问题缺乏理解,容易受到输入干扰等。目前认为GPT-4的幻觉与其涌现能力具有相关性。
chatgpt,1750亿参数。
chatglm,1300亿参数。
# Few shot
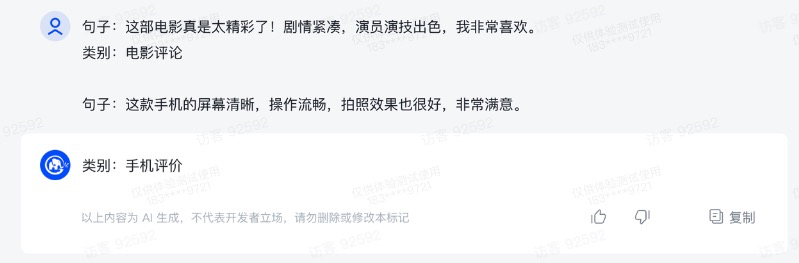
Few shot的能力:提到我们可以给模型一些示例,从而让模型返回更符合我们需求的答案。
- 少量示例:大模型能够仅通过几个示例样本来进行学习和理解。相比传统的机器学习方法,大模型不需要依赖大量的标注数据来训练,从而降低了数据收集和标注的成本和时间。
- 泛化能力:大模型能够从少量示例中抽取共同的特征和模式,然后应用这些知识到新的类似任务中。它能够利用其在大规模数据集上训练的经验和语言理解能力,对新的问题进行推理和分类。
# 思维链
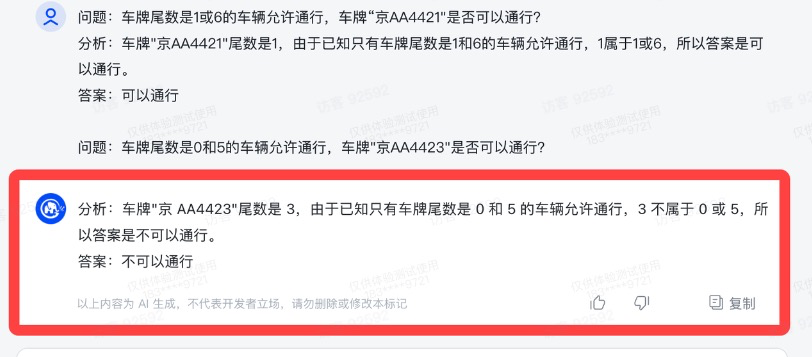
思维链(Chain of Thought)可视为大语言模型涌现出来的核心能力之一。
思维链形成机制可以解释为模型通过学习大量的语言数据来构建一个关于语言结构和意义的内在表示,通过一系列中间自然语言推理步骤来完成最终输出。思维链是ChatGPT和GPT-4能让大众感觉到语言模型“像人”的关键特性。 对创企来说,完成思维链的训练,才算真正拿到了这波大模型AI竞技的入场券。
一般认为模型的思维推理能力与模型参数大小有正相关趋势,一般是突破一个临界规模(大概62B,B代表10亿),模型才能通过思维链提示的训练获得相应的能力。
通过向大语言模型展示一些少量的样例,并在样例中解释推理过程,大语言模型在回答提示时也会显示推理过程。这种推理的解释往往会引导出更准确的结果。
# 大模型的缺陷
致命的缺陷,那就是大模型的生成”幻觉“(Hallucination)问题,也就是经常遇到的“一本正经的胡说八道”。生成幻觉通常是指模型按照流畅正确的语法规则产生的包含虚假信息甚至毫无意义的文本。这对于大模型的实际部署是一个非常具有挑战性的问题。
# LLM
Large Language Model(大型语言模型):LLM可以指代大型的自然语言处理(NLP)模型,如GPT-3(Generative Pre-trained Transformer 3)等。这些模型使用深度学习技术,具有大量的参数和复杂的结构,能够生成高质量的自然语言文本。
大语言模型是基于概率的生成模型的一种。它可以根据给定的输入上下文生成可能的输出文本。这种模型的训练过程是基于概率模型的最大似然估计,通过学习大量的文本数据来捕捉语言的统计规律。
"基于概率模型的最大似然估计"是一种统计学方法,用于估计概率模型中的参数。在这种方法中,我们假设观测数据是由一个特定的概率模型生成的,并且我们的目标是找到使得观测数据出现的概率最大的参数值。
最大似然估计的基本思想是,通过最大化观测数据的似然函数来确定参数的值。似然函数是一个关于参数的函数,表示给定参数值时观测数据出现的概率。最大似然估计的目标是找到使得似然函数取得最大值的参数值。
最大似然估计在统计学中被广泛应用,可以用于估计各种概率模型的参数,如高斯分布、伯努利分布、多项式分布等。它是一种常用的参数估计方法,具有良好的性质和统计学意义。
概率模型可以理解为,它只是读过了很多文字,然后在你问出问题后,试图根据问题来检索它所读过的那些文字,然后拼凑出句子。
如果你问它一些它没有读过的文字,它同样会给出它认为概率最高的答案,但那个答案可能会是错误的
# 发展史
大预言模型经历了5个阶段,分别是:基于n-gram的语言模型、基于神经网络的语言模型、递归神经网络语言模型、长短时记忆网络语言模型、门控循环单元语言模型、大规模预训练语言模型。
1.基于n-gram的语言模型
在计算机科学早期,基于n-gram的语言模型是一种常见的统计语言模型。它通过统计一个词或者一组词在语言中出现的频率,来计算一个句子的概率。这种方法虽然简单,但是在语言模型的设计中起到了重要作用。
2.基于神经网络的语言模型
随着深度学习技术的发展,基于神经网络的语言模型开始受到广泛关注。这种方法使用一个深度神经网络来学习语言的规律和模式。在这个神经网络中,每个词被表示为一个向量,然后将它们送入神经网络进行训练。这种方法可以避免使用n-gram方法中需要存储的大量数据,从而大大提高了语言模型的性能和效率。
3.递归神经网络语言模型
递归神经网络(RNN)是一种特殊的神经网络,可以处理序列数据。RNN语言模型使用RNN来对句子中的词进行建模,从而可以考虑上下文信息,进一步提高模型的性能。然而,RNN语言模型存在着梯度消失和梯度爆炸等问题,限制了其在长序列数据处理中的表现。
4.长短时记忆网络语言模型
为了解决RNN语言模型中的梯度消失和梯度爆炸等问题,长短时记忆网络(LSTM)被引入到语言模型中。LSTM可以更好地捕捉长序列中的依赖关系,从而提高了模型的性能和泛化能力。
5.门控循环单元语言模型
门控循环单元(GRU)是LSTM的一个变种,它可以在更简单的结构下实现类似的处理效果。与LSTM相比,GRU模型的参数更少,训练速度更快,因此在一些应用场景中表现更优。
6.大规模预训练语言模型
近年来,大规模预训练语言模型已经成为了大语言模型的主流发展方向。这种方法通过在大规模文本数据上进行自监督学习,构建一个预训练的语言模型,并在此基础上进行微调,来完成各种自然语言处理任务。例如,BERT、GPT和XLNet等模型已经在各种自然语言处理任务中取得了很好的表现。
# 网络架构及技术
我们可以将LLM分成2类:Encoder-Decoder(或者Encoder-Only)和Decoder-Only。它们的技术特点和模型代表如下:
| 模型架构 | 训练方式 | 模型类型 | 预训练任务 | 代表性模型 |
|---|---|---|---|---|
| Encoder-Decoder或者 Encoder-Only(BERT样式) | Masked语言模型 | 判别式(Discriminative) | 预测masked单词 | ELMo, BERT, RoBERTa, DistilBERT, BioBERT, XLM, Xlnet, ALBERT, ELECTRA, T5, XLM-E, ST-MoE, AlexaTM |
| Decoder-Only (GPT样式) | 自回归语言模型 | 生成式(Generative) | 预测下一个单词 | GPT-3, OPT,PaLM, BLOOM, GLM, MT-NLG, GLaM,Gopher, chinchilla, LaMDA, GPT-J, LLaMA, GPT-4, BloombergGPT |
自回归语言模型在最近发布的模型中都是十分流行的。通过下图对这几类模型做了很好的总结:
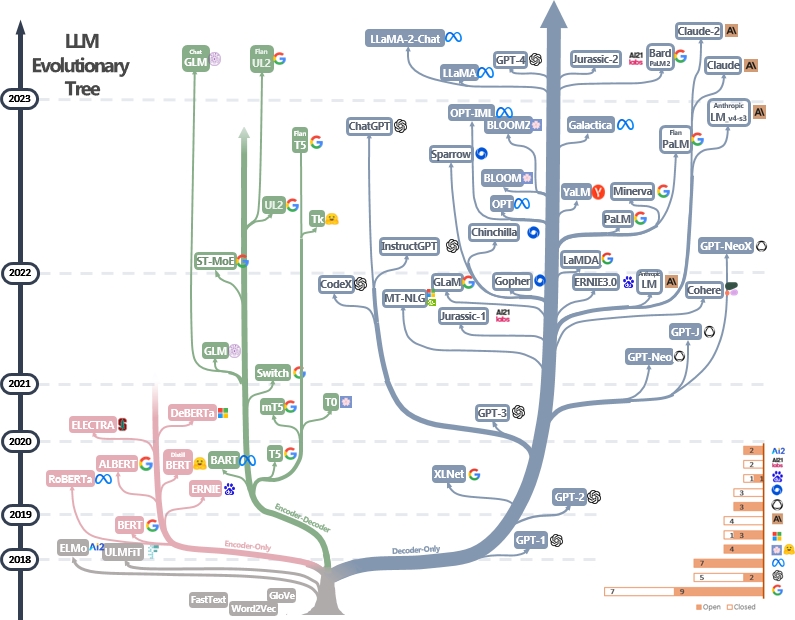
首先红色的分支是指Encoder-Only技术,最早是BERT模型,到了2020年之后,这类技术基本已经不再发展。中间绿色部分是Encoder-Decoder类型,近几年似乎也就是Google坚持这类路线的模型较多。
绿色的Encoder-Decoder模型相比Encoder-Only模型,通常具有更强的序列学习和生成能力,尤其擅长实现输入序列到输出序列的结构映射,所以在机器翻译、文摘生成和聊天机器人等任务上有更好的应用前景。但Encoder-Only的模型结构简单, training 和inference 速度更快,在一些简单分类或标注任务上也具有优势。
最后一类蓝色的是Decoder-Only类型,也是最繁荣发展的一类transformer模型。最早是GPT-1提出,此后包括MetaAI、百度、Google、OpenAI、EleutherAI等公司都提出了这种架构的模型。
Decoder-only模型仅具有解码器部分,没有编码器部分。Decoder-only模型相比Encoder-Decoder模型有以下主要优势:
- 结构简单,训练和推理速度快。由于没有Encoder部分,整个模型的参数和运算量都减少了一半以上,这使得Decoder-only模型训练和部署起来更加高效。
- 适用于纯生成任务。Decoder-only模型专注于生成输出序列,而不需要考虑编码输入信息的问题,所以更适用于如文本生成、情节生成和对话生成等纯生成任务。
- 避免了Encoder-Decoder训练中的一些难点。仅训练一个Decoder可以避免诸如不同权重初始化、信息瓶颈等 Encoder-Decoder训练过程中的一些难题。
- Decoder自我监督。在Decoder-only模型的训练中,上一步生成的输出作为下一步的输入,这实现了Decoder部分的自我监督,有利于生成更为连贯和结构性的输出序列。
# 基座模型
基础语言模型(Basic Language Model)是指只在大规模文本语料中进行了预训练的模型,未经过指令和下游任务微调、以及人类反馈等任何对齐优化。
通俗的讲,一个人掌握了知识,但并不一定会考试,比如
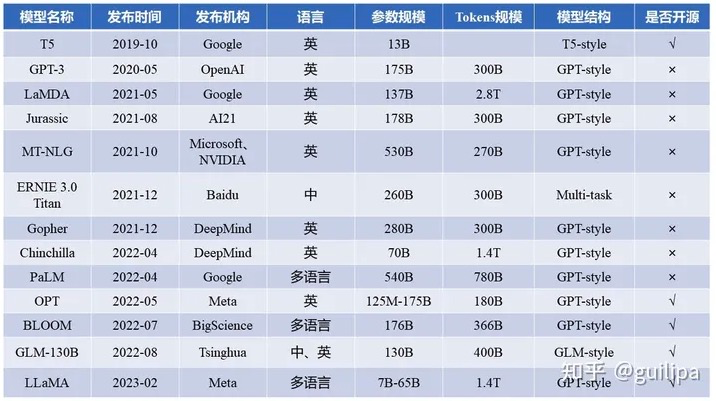
# T5
T5 是谷歌提出了一个统一预训练模型和框架,模型采用了谷歌最原始的 Encoder-Decoder Transformer结构。T5将每个文本处理问题都看成“Text-to-Text”问题,即将文本作为输入,生成新的文本作为输出。通过这种方式可以将不同的 NLP 任务统一在一个模型框架之下,充分进行迁移学习。为了告知模型需要执行的任务类型,在输入的文本前添加任务特定的文本前缀 (task-specific prefifix ) 进行提示,这也就是最早的 Prompt。也就说可以用同样的模型,同样的损失函数,同样的训练过程,同样的解码过程来完成所有 NLP 任务。
T5 本身主要是针对英文训练,谷歌还发布了支持 101 种语言的 T5 的多语言版本 mT5[2] (opens new window)。
# GTP-3
大语言模型中最具代表和引领性的就是发布 ChatGPT 的 OpenAI 的 GPT 系列模型 (GPT-1、GPT-2、GPT-3、GPT-3.5、GPT-4),并且当前大部分大语言模型的结构都是 GPT-style ,文章生成式预训练模型 (opens new window)中介绍了GPT-1/2/3, 且从 GPT-3 开始才是真正意义的大模型。
GPT-3 是 OpenAI 发布的 GPT 系列模型的一个,延续了 GPT-1/2 基于Transformer Decoder 的自回归语言模型结构,但 GPT-3 将模型参数规模扩大至 175B, 是 GPT-2 的 100 倍,从大规模数据中吸纳更多的知识。GPT-3不在追求 zero-shot 的设定,而是提出 In-Context Learning ,在下游任务中模型不需要任何额外的微调,利用 Prompts 给定少量标注的样本让模型学习再进行推理生成。就能够在只有少量目标任务标注样本的情况下进行很好的泛化,再次证明大力出击奇迹,做大模型的必要性。通过大量的实验证明,在 zero-shot、one-shot 和 few-shot 设置下,GPT-3 在许多 NLP 任务和基准测试中表现出强大的性能,只有少量目标任务标注样本的情况下进行很好的泛化,再次证明大力出击奇迹,做大模型的必要性。
# LLaMA
LLaMA 是 Meta AI 发布的包含 7B、13B、33B 和 65B 四种参数规模的基础语言模型集合,LLaMA-13B 仅以 1/10 规模的参数在多数的 benchmarks 上性能优于 GPT-3(175B),LLaMA-65B 与业内最好的模型 Chinchilla-70B 和 PaLM-540B 比较也具有竞争力。
这项工作重点关注使用比通常更多的 tokens 训练一系列语言模型,在不同的推理预算下实现最佳的性能,也就是说在相对较小的模型上使用大规模数据集训练并达到较好性能。Chinchilla 论文中推荐在 200B 的 tokens 上训练 10B 规模的模型,而 LLaMA 使用了 1.4T tokens 训练 7B的模型,增大 tokens 规模,模型的性能仍在持续上升。
# GLM-130B
GLM-130B 是清华大学与智谱AI共同研制的一个开放的双语(英汉)双向密集预训练语言模型,拥有 1300亿个参数,使用通用语言模型(General Language Model, GLM (opens new window))的算法进行预训练。 2022年11月,斯坦福大学大模型中心对全球30个主流大模型进行了全方位的评测,GLM-130B 是亚洲唯一入选的大模型。GLM-130B 在广泛流行的英文基准测试中性能明显优于 GPT-3 175B(davinci),而对 OPT-175B 和 BLOOM-176B 没有观察到性能优势,它还在相关基准测试中性能始终显著优于最大的中文语言模型 ERNIE 3.0 Titan 260B。GLM-130B 无需后期训练即可达到 INT4 量化,且几乎没有性能损失;更重要的是,它能够在 4×RTX 3090 (24G) 或 8×RTX 2080 Ti (11G) GPU 上有效推理,是使用 100B 级模型最实惠的 GPU 需求。
INT4量化是指将机器学习模型中的浮点数运算替换为整数运算,以减少模型推理的能耗和延迟。这种量化方法主要应用于神经网络推理,尤其是深度学习模型的部署。INT4量化算法通过对模型参数进行缩放和偏移,将浮点数转换为等效的整数,从而在保证模型精度的前提下,降低计算复杂度和存储需求。这种量化方法已被广泛用于各种硬件平台和实际应用中,以实现更高效和节能的AI推理。
# 指令模型
指令模型(Instruction-Finetuned Language Model),这里的 Instruction[19] (opens new window) (指令)是指通过自然语言形式对任务进行描述。如下图所示,对于翻译任务,在对需要翻译的句子 "I Love You." 前加入任务指令 "Translate the given English utterance to French script." 告诉模型要执行的任务和要求。这种方式符合模型生成的工作模型,最重要的是对于未知任务具有较好的 zero-shot 性能表现。通过将各种不同的任务转化为指令数据形式,对语言模型进行进一步微调。
通俗的讲,就是刷题。
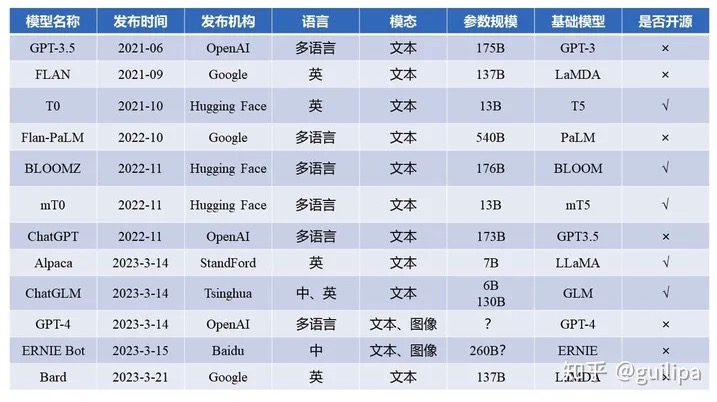
# ChatGPT
ChatGPT 是在 GPT-3.5 基础上进行微调得到的,微调时使用了从人类反馈中进行强化学习的方法(Reinforcement Learning from Human Feedback,RLHF),这里的人类反馈其实就是人工标注数据,来不断微调 LLM,主要目的是让LLM学会理解人类的命令指令的含义(比如文生成类问题、知识回答类问题、头脑风暴类问题等不同类型的命令),以及让LLM学会判断对于给定的prompt输入指令(用户的问题),什么样的答案输出是优质的(富含信息、内容丰富、对用户有帮助、无害、不包含歧视信息等多种标准)。
其实从 GPT-1到 GPT-3.5 可以发现更大的语言模型虽然有了更强的语言理解和生成的能力,但并不能从本质上使它们更好地遵循或理解用户的指令意图。例如,大型语言模型可能会生成不真实、有害或对用户没有帮助的输出,原因在于这些语言模型预测下一个单词的训练目标与用户目标意图是不一致的。为了对齐语言模型于人类意图,ChatGPT展示了一种途径,可以引入人工标注和反馈,通过强化学习算法对大规模语言模型进行微调,在各种任务上使语言模型与用户的意图保持一致,输出人类想要的内容。
# Alpaca
Alpaca(羊驼)模型是斯坦福大学基于 Meta 开源的 LLaMA-7B 模型微调得到的指令遵循(instruction-following)的语言模型。在有学术预算限制情况下,训练高质量的指令遵循模型主要面临强大的预训练语言模型和高质量的指令遵循数据两个挑战,作者利用 OpenAI 的 text-davinci-003 模型以 self-instruct (opens new window) 方式生成 52K 的指令遵循样本数据,利用这些数据训练以有监督的方式训练 LLaMA-7B 得到 Alpaca 模型。在测试中,Alpaca 的很多行为表现都与 text-davinci-003 类似,且只有 7B 参数的轻量级模型 Alpaca 性能可与 GPT-3.5 这样的超大规模语言模型性能媲美。
# ChatGLM
ChatGLM 是清华大学知识工程(KEG)实验室与其技术成果转化的公司智谱AI基于此前开源的 GLM-130B (opens new window) 千亿基座模型研制,是一个初具问答和对话功能的千亿中英语言模型。ChatGLM 参考了 ChatGPT 的设计思路,在千亿基座模型 GLM-130B 中注入了代码预训练,通过有监督微调(Supervised Fine-Tuning)、反馈自助(Feedback Bootstrap)、人类反馈强化学习(Reinforcement Learning from Human Feedback) 等技术实现人类意图对齐。
2023年6月14日,开源了62 亿参数的 ChatGLM-6B (opens new window),结合模型量化技术,用户可以在消费级的显卡上进行本地部署(INT4 量化级别下最低只需 6GB 显存),虽然规模不及千亿模型,但大大降低了用户部署的门槛,并且已经能生成相当符合人类偏好的回答。
2023年6月25日,二代模型 ChatGLM2-6B 模型开源,更强大的性能(MMLU [+23%]、C-Eval [+33%]、GSM8K [+571%] )、更长的上下文(2K扩展到8K)、更高效的推理(推理速度提升42%)、更开放的开源协议。同时也推出了ChatGLM2-6B、ChatGLM2-12B、ChatGLM2-32B、ChatGLM2-66B、ChatGLM2-130B不同参数规模的模型。
# 预训练
# 什么是预训练?
大模型的预训练是指在使用大量数据集进行训练的大型深度学习模型中,预先训练权重的过程。这个过程通常在非常大的数据集上进行,例如在包含数百万甚至数十亿样本的数据集上训练模型。预训练模型通常包含大量的参数,因此需要大量的计算资源和内存。
预训练属于迁移学习的范畴。现有的神经网络在进行训练时,一般基于反向传播(Back Propagation,BP)算法,先对网络中的参数进行随机初始化,再利用随机梯度下降(Stochastic Gradient Descent,SGD)等优化算法不断优化模型参数。而预训练的思想是,模型参数不再是随机初始化的,而是通过一些任务进行预先训练,得到一套模型参数,然后用这套参数对模型进行初始化,再进行训练。
预训练模型的主要优点是可以利用大规模数据集和计算资源来提高模型的泛化能力。由于预训练模型已经在大量数据上进行了训练,因此它们可以在类似的数据集上进行微调,从而在较少的训练样本上获得更好的性能。此外,预训练模型还可以作为一个强大的特征提取器,提取出文本、图像或其他数据的特征,以便于后续的分类或回归任务。
通俗的讲,预训练是将大量低成本收集的训练数据放在一起,经过某种预训练的方法去学习其中的共性,然后将其中的共性 “移植” 到特定任务的模型中,再使用相关特定领域的少量标注数据进行 “微调”。因此,模型只需要从“共性” 出发,去 “学习” 该特定任务的 “特殊” 部分。
举例:让一个完全不懂英文的人去做英文法律文书的关键词提取的工作会完全无法进行,或者说他需要非常多的时间去学习,因为他现在根本看不懂英文。但是,如果让一个英语为母语但没接触过此类工作的人去做这项任务,他可能只需要相对比较短的时间学习如何去提取法律文书的关键词就可以上手这项任务。在这里,英文知识就属于 “共性” 的知识,这类知识不必要只通过英文法律文书的相关语料进行学习,而是可以通过大量英文语料,不管是小说、书籍,还是自媒体,都可以是学习资料的来源。在该例中,让完全不懂英文的人去完成这样的任务,这就对应了传统的直接训练方法,而完全不懂英文的人如果在早期系统学习了英文,再让他去做同样的任务,就对应了 “预训练 + 微调” 的思路,系统的学习英文即为 “预训练” 的过程。
大语言模型的预训练是指搭建一个大的神经网络模型并喂入海量的数据以某种方法去训练语言模型。大语言模型预训练的主要特点是训练语言模型所用的数据量够多、模型够大。
# 模型如何够大?
大模型的大小取决于其参数量,参数量是指模型中需要学习的可调整参数的数量。参数量越大,模型的容量和表达能力就越强,可以更好地拟合复杂的数据和任务。
以下是影响大模型参数量的几个因素:
- 模型架构:模型的架构决定了参数的数量。不同的架构具有不同数量的层、单元和连接,从而影响参数量。例如,Transformer模型通常具有大量的自注意力头和多层结构,因此参数量较大。
- 模型层数:模型的层数指的是模型中的隐藏层数量。增加层数可以增加模型的深度,从而提高模型的表达能力。然而,层数增加也会导致参数量的增加。
- 模型宽度:模型的宽度指的是每个隐藏层中的单元数量。增加宽度可以增加模型的容量,使其能够处理更多的特征和信息。但是,宽度的增加也会导致参数量的增加。
- 输入维度:模型的输入维度也会影响参数量。如果输入维度较高,模型需要更多的参数来处理输入数据。
需要注意的是,参数量的增加并不总是意味着模型性能的提升。过大的模型可能会导致过拟合问题,而且训练和推理的计算成本也会增加。因此,在选择模型大小时,需要综合考虑模型的性能需求、计算资源和数据规模等因素。
# 基本原理
大语言模型预训练采用了 Transformer 模型的解码器部分,由于没有编码器部分,大语言模型去掉了中间的与编码器交互的多头注意力层。如下图所示,左边是 Transformer 模型的解码器,右边是大语言模型的预训练架构
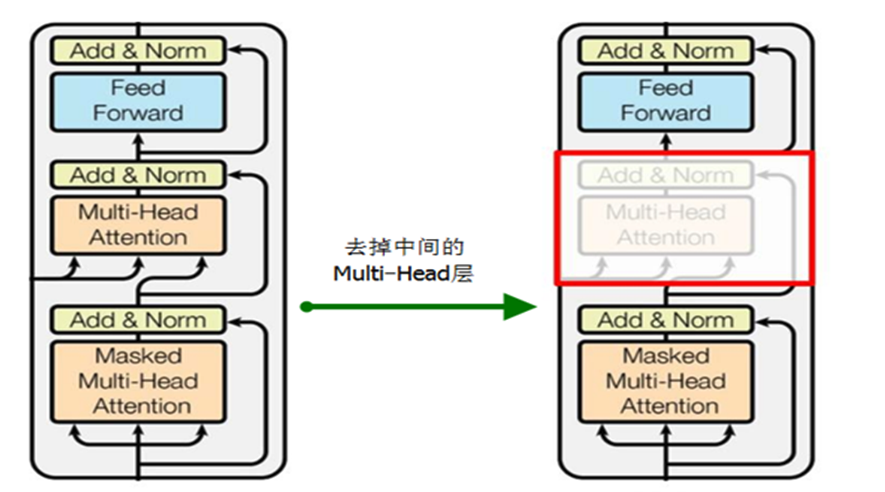
大语言模型预训练是通过上文的词来预测下一个词,属于无监督的预训练。比如,给定一个无监督的语料U={u1,...,un},而预训练语言模型是要使得下面式子最大化:
$L1(U)=ΣiP(ui∣ui−k,...,ui−1;Θ)$
# 预训练步骤
- 数据收集:首先,需要收集大量的文本数据作为预训练的输入。这些数据可以来自互联网、书籍、新闻文章、维基百科等多个来源,以确保模型能够学习到广泛的语言知识和语义关系。
- 数据预处理:在进行预训练之前,需要对收集到的文本数据进行预处理。这包括分词、标记化、去除停用词、处理特殊字符等操作,以便将文本数据转化为模型可以处理的格式。
- 模型架构:选择适当的模型架构,如Transformer,作为预训练模型的基础。Transformer是一种基于自注意力机制的深度学习模型,被广泛用于自然语言处理任务。
- 预训练过程:使用预处理后的文本数据,将其输入到模型中进行训练。预训练过程通常采用无监督学习的方式,即模型在没有标签或任务指导的情况下学习语言的统计规律和语义关系。这个过程可以通过最大似然估计等方法来优化模型参数。
- 微调和迁移学习:在预训练完成后,可以使用微调或迁移学习的方法,将预训练模型应用于特定的任务。通过在特定任务上进行有监督的训练,模型可以进一步适应任务的要求,并提高性能。
# 微调
# 什么是微调?
大模型微调是指针对特定任务对预训练的大模型进行微小调整。它是使用少量目标领域的样本数据进行训练,以优化模型在特定任务上的性能。大模型微调可以看作是在预训练模型的基础上,对模型的特定功能进行“调教”,即通过输入特定领域的数据集,让模型学习这个领域的知识,从而让大模型能够更好的完成特定领域的NLP任务,例如情感分析、命名实体识别、文本分类、对话聊天等。
# 微调方式
微调预训练模型的方法:(TODO模型分哪些层,作用)
- 微调所有层:将预训练模型的所有层都参与微调,以适应新的任务。
- 微调顶层:只微调预训练模型的顶层,以适应新的任务。
- 冻结底层:将预训练模型的底层固定不变,只对顶层进行微调。
- 逐层微调:从底层开始,逐层微调预训练模型,直到所有层都被微调。
- 迁移学习:将预训练模型的知识迁移到新的任务中,以提高模型性能。这种方法通常使用微调顶层或冻结底层的方法。
目前来说,我们常用的方法一般是前三种。简单来说模型的参数就类比于,一个在大学学习到所有专业的知识的大学生,基于过往的学习经验以及对生活中的一些事情,已经有了属于自己的一套学习方法思维逻辑。而微调则是一个大学生毕业后从事某一种行业的工作,那他就要开始学习工作上的内容,来产出工作的成果。下面我们就来介绍一些常用的微调方法。
# 1.Fine tuning
Fine tuning是一种在自然语言处理(NLP)中使用的技术,用于将预训练的语言模型适应于特定任务或领域。Fine tuning的基本思想是采用已经在大量文本上进行训练的预训练语言模型,然后在小规模的任务特定文本上继续训练它。
经典的Fine tuning方法包括将预训练模型与少量特定任务数据一起继续训练。在这个过程中,预训练模型的权重被更新,以更好地适应任务。所需的Fine-tuning量取决于预训练语料库和任务特定语料库之间的相似性。如果两者相似,可能只需要少量的Fine tuning。如果两者不相似,则可能需要更多的Fine tuning。

# 2.Prompt tuning
参数高效性微调方法中实现最简单的方法还是Prompt tuning(也就是我们常说的P-Tuning),固定模型前馈层参数,仅仅更新部分embedding参数即可实现低成本微调大模型
经典的Prompt tuning方式不涉及对底层模型的任何参数更新。相反,它侧重于精心制作可以指导预训练模型生成所需输出的输入提示或模板。主要结构是利用了一个prompt encoder(BiLSTM+MLP),将一些pseudo prompt先encode(离散token)再与input embedding进行拼接,同时利用LSTM进行 Reparamerization 加速训练,并引入少量自然语言提示的锚字符(Anchor,例如Britain)进一步提升效果。然后结合(capital,Britain)生成得到结果,再优化生成的encoder部分。但是P-tuning v1有两个显著缺点:任务不通用和规模不通用。在一些复杂的自然语言理解NLU任务上效果很差,同时预训练模型的参数量不能过小。
# Prefix Tuning
如果分析 P-tuning,那不得不提到prefix-tuning技术,相对于fine-tuning,在调节模型的过程中只优化一小段可学习的continuous task-specific vector(prefix)而不是整个模型的参数。
Prefix Tuning针对不同的模型结构有设计不同的模式,以自回归的模型为例,不再使用token去作为前缀,而是直接使用参数作为前缀,比如一个$l × d$的矩阵$P$作为前缀,但直接使用这样的前缀效果不稳定,因此使用一个MLP层重参数化,并放大维度$d$,除了在embedding层加入这个前缀之外,还在其他的所有层都添加这样一个前缀。最后微调时只调整前缀的参数,大模型的参数保持不变。保存时只需要为每个任务保存重参数的结果即可。
# 3.P-tuning v2
V2版本主要是基于P-tuning和prefix-tuning技术,引入Deep Prompt Encoding和Multi-task Learning等策略进行优化的。
实验表明,仅精调0.1%参数量,在330M到10B不同参数规模LM模型上,均取得和Fine-tuning相比肩的性能
 (opens new window)
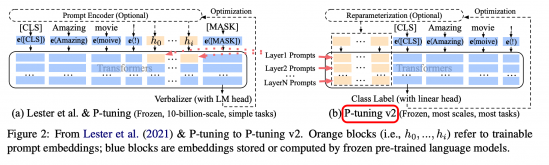
下面是v1和v2框架对比,我们可以看到右侧的p-tuning v2中,将continuous prompt加在序列前端,并且每一层都加入可训练的prompts。在左图v1模型中,只将prompt插入input embedding中,会导致可训练的参数被句子的长度所限制。此外P-Tuning v2还包括以下改进:
(opens new window)
下面是v1和v2框架对比,我们可以看到右侧的p-tuning v2中,将continuous prompt加在序列前端,并且每一层都加入可训练的prompts。在左图v1模型中,只将prompt插入input embedding中,会导致可训练的参数被句子的长度所限制。此外P-Tuning v2还包括以下改进:
- 移除了Reparamerization加速训练方式;
- 采用了多任务学习优化:基于多任务数据集的Prompt进行预训练,然后再适配的下游任务。
- 舍弃了词汇Mapping的Verbalizer的使用,重新利用[CLS]和字符标签,跟传统finetune一样利用cls或者token的输出做NLU,以增强通用性,可以适配到序列标注任务。
 (opens new window)
总而言之,P-tuning v2就是将Prefix-tuning应用到NLU任务上的一种方法。同时由于P-tuning v2每层插入了token,增大模型训练的改变量,所以更加适用于小一点的模型。
(opens new window)
总而言之,P-tuning v2就是将Prefix-tuning应用到NLU任务上的一种方法。同时由于P-tuning v2每层插入了token,增大模型训练的改变量,所以更加适用于小一点的模型。

# 4. Lora
Lora的本质就是对所有权重矩阵套了一层“壳”,这些壳会对原来的预训练权重矩阵进行加减使其更加适合下游任务,即实现微调。他的假设前提是预训练语言模型具有低的”内在维度”,因此认为在模型适配下游任务的过程中,权重更新也应该具有低的“内在秩”。
在对大语言模型进行微调的公式可以简化为下面的公式 $$ W=W 0 +ΔW.W∈R d×k ,W 0 ∈R d×k $$ 其中W是微调微调过后的矩阵权重(是大语言模型中的对应的稠密层,一般这些矩阵都是满秩的),$W_0$ 是预训练的权重,$\Delta W$是通过微调而更新的梯度。将上面的$\Delta W$做一些变换,将他变成两个矩阵相乘 $$ W=W 0 +ΔW=W 0 +BA.B∈R d×r ,A∈R r×k $$ 在里面引入了秩r,$r << min(d,k)$,在训练过程中lora会冻结预训练权重$W_0$,只训练$A$和$B$,减少了需要训练的参数的量,一般来讲,对于lora微调模型来讲r设置的越大其微调效果会越好。
LoRA算法的核心思想是,将原始矩阵A AA分解为两个低秩矩阵X XX和Y YY的乘积形式,即$A=X\cdot Y$。具体地,LoRA算法会首先对原始矩阵进行SVD分解,得到矩阵$A=U\Sigma V^T$,其中$U$和$V$分别是$AA^T$和 $A^TA$的特征向量矩阵,$\Sigma$是奇异值矩阵。然后,LoRA算法会取$U$的前$k$列和$V$的前$k$行,得到低秩矩阵$X=U(:,1:k)$和$Y=V(1:k,:)$,其中$k$是预设的参数,表示矩阵$A$的秩。最后,LoRA算法将近似矩阵$A_k=X\cdot Y$作为原始矩阵$A$的近似,即$A_k \approx A$。
 (opens new window)
(opens new window)
最终我们得到的一个权重文件会是各层的$BA$,在推理时是需要计算一下$W = W_0 + BA$,就可以得到最终需要的微调之后的模型权重,该方法的好处如下所示
- 减少了需要推理的参数量
- 相较于添加adapter层的方式去微调模型,因为他并没有在模型中添加额外的层,只是在原来的权重上进行权重的加减,微调前后模型的推理时间不变
- 因为他最后生成的权重是各层的$BA$,并没有改变原模型的权重参数,所以其结果相当于一个插件,可以即插即用,可以为多个不同的微调任务生成各自的lora微调权重值,也方便存储。
一般在使用lora去对模型卫星微调的时候需要注意的参数就两个:r和lora_target_modules 。前者决定了lora微调时构造的矩阵的秩的大小(这里也可以简单的理解为矩阵B和A的大小),以及在大语言模型中应用的不同模块。后者模块的具体名称需要依据不同的模型去决定。
# 5.RLHF—人类反馈强化学习
RLHF 的思想就是使用强化学习的方式直接优化带有人类反馈的语言模型。RLHF 使得在一般文本数据语料库上训练的语言模型能和复杂的人类价值观对齐。 RLHF 是一项涉及多个模型和不同训练阶段的复杂概念,一般会分为三步,这也是一个生成自己大模型所必需的。
GPT-4/ChatGPT与GPT-3.5的主要区别在于,新加入了被称为RLHF(Reinforcement
Learning from Human Feedback,人类反馈强化学习)的技术
# 6.DeepSpeed ZeRO——零冗余优化
Deepspeed是微软的大规模分布式训练工具。专门用于训练超大模型。其具有的3D 并行同时解决了训练万亿参数模型的两个基本挑战:显存效率和计算效率。因此,DeepSpeed 可以扩展至在显存中放下最巨大的模型,而不会牺牲速度。
# 7.Accelerate
Accelerate[7]库提供了简单的 API,使我们可以在任何类型的单节点或分布式节点(单CPU、单GPU、多GPU 和 TPU)上运行,也可以在有或没有混合精度(fp16)的情况下运行。
# 8.Autocast
autocast是在GPU上训练时一种用于降低显存消耗的技术。原理是用更短的总位数来保存浮点数,能够有效将显存消耗降低,从而设置更大的batch来加速训练。但会造成精度的损失,导致收敛效果也会变差。
# Prompt
# prompt是什么
Prompt就是给AI的指令,引导模型生成响应的回答。
“中国的首都是哪里?”
“中国的首都是北京”
2
# prompt工程是什么
提示工程(Prompt Engineering)是指根据特定的目标和语境设计出一系列问题或任务,以便使用大模型生成有关主题或主题领域的连贯和有意义的文本。提示工程的目标是通过精心设计提示以从模型中引出所需的响应,来提高生成文本的质量和相关性。提示工程与思维链的产生密不可分,也是目前自然语言编程的理论基础。
对于基于转换器的大型语言模型(如OpenAI的GPT系列),输入提示在提高模型理解、回答问题、生成有用输出等方面具有关键作用。Prompt工程包括问题构建、上下文引导、间接引导和分步引导等多个方面,以帮助AI模型更好地理解和解决各种问题。
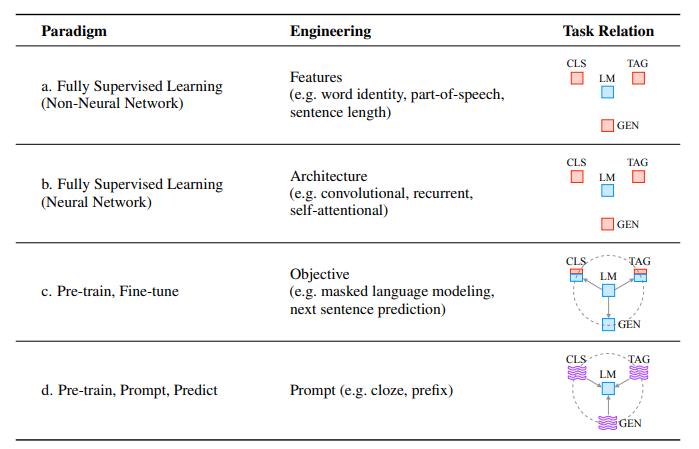
▲语言模型的4种研究范式(来源:卡内基梅隆大学)
大概在2017-2019年间,语言模型的研究重心逐渐从传统特定领域的有监督学习模式(基于非神经网络或神经网络)转移到预训练模型上。在那时,基于预训练语言模型的研究范式通常是“预训练+精调”(Pre-train+Fine-tune),即在精调阶段,根据下游任务对预训练模型进行微调,以获得更好效果。
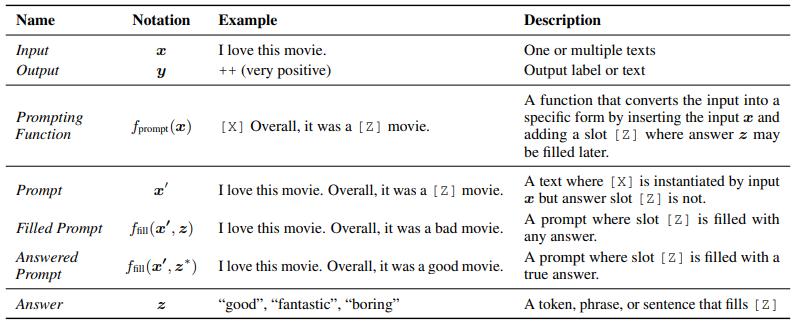
这里举一个填充提示的简单例子。(上图)我们从输入x(比如电影评论)开始,然后输出期望值y。其中一个任务是使用提示函数重新模板化此输入,其输出表示为x'。此时语言模型的任务仅仅是预测z值(句子中的一个词)来代替占位符Z。然后对于Z被答案填充的提示,我们将其称为填充提示。通过这一提示方式,在对应细分场景下,语言模型将原来的问题的期望值y(一句话)简化为答案z(一个词)的计算,明显降低了应答的复杂度。

# prompt的结构
- context(可选)
- 角色
- 任务
- 知识
- Instruction(必选)
- 步骤
- 思维链
- 示例
- input data(必选)
- 句子
- 文章
- 问题
- output indicator(可选)
示例
你是一名机器学习工程师,负责开发一个文本分类模型,该模型可以将电影评论分为正面评价和负面评价两类。
请根据以下上下文和输入,对文本进行分类,并给出相应的输出类别。
示例:
输入文本:这部电影真是太精彩了!演员表现出色,剧情扣人心弦,强烈推荐!
输出类别:正面评价
输入文本:这部电影真是太精彩了!演员表现出色,剧情扣人心弦,强烈推荐!
输出类别:
2
3
4
5
6
7
8
9
10
# 如何写出好的prompt
# 清晰和明确的指令
举例
"请解释什么是人工智能?"
"列出三个关于太阳系的事实。"
"回答以下数学问题:2 + 2 = ?"
VS
"谈谈科技。"
"讲个笑话。"
"说一些关于历史的事情。"
# 分隔符
- """..."""(推荐)
- <...>
- ---...---
# 样例数据
请按照以上格式直接回答问题。只能给出答案,不要生产其他内容。
问题:日本的首都是哪里?
答案:东京
问题:法国的首都是哪里?
答案:
2
3
4
5
6
7
# 思维链
你是一个智能助理,用户会称呼你小爱或小爱同学,你需要帮用户结构化记录生日信息、物品存放信息、月经信息
用户输入是一句非常口语化的指令,你需要记录用户指令,并从用户的指令中结构化的输出提取出信息
输出完毕后结束,不要生成新的用户输入,不要新增内容
1.提取话题,话题只能是:生日、纪念日、月经、物品存放。
2.提取目的,目的只能是:记录、预测、查询、庆祝、设置、记录物品、拿到物品、寻找、删除、修改。
3.提取人物,人物指:过生日的人物、过纪念日的人物、来月经的人物、放物品的人物。输出只能是:我,爸爸、妈妈、孩子、爱人、恋人、朋友、哥哥、姐姐。没有写“无”
4.提取人关系,关系指人物与用户的关系,关系只能是:本人、亲人、配偶、朋友、未知、待查询。没有写“无”
5.提取时间,比如:今天、3月1日、上个月、农历二月初六、待查询。没有写“无”
6.提取时间类型,时间类型只能是:过生日的时间、过纪念日的时间、月经开始时间、月经结束时间。 没有写“无”
7.提取物品,比如:衣服、鞋子、书、电子产品、其它。
8.提取物品对应位置,比如:衣柜、书柜、鞋柜、电子产品柜、待查询。
9.按示例结构输出内容,结束
用户:充电器放包里了
话题:物品存放
目的:记录
人物:无
关系:无
时间:无
时间类型:无
物品:充钱器
位置:包里
用户:今天我过生日
话题:生日
目的:记录
人物:我
关系:本人
时间:今天
时间类型:生日时间
物品:无
位置:无
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
# 计算步骤
小明有5个苹果,他又买了2袋子苹果,每个袋子里有3个苹果,小明一共有几个苹果?
计算过程:
1,小明开始有5个苹果。
2,2个袋子里,每个袋子里有3个苹果。3*2=6
3,一共有5+6=11个苹果。
答案:
小明一共有11个苹果。
小明有11个苹果,他又买了3袋子苹果,每个袋子里有4个苹果,小明一共有几个苹果?
2
3
4
5
6
7
8
9
10
技巧
- 流程简单:过于复杂的流程会增加大模型出错概率,应该尽量减少流程
- 理解语义:不能强制大模型输出某些内容,要根据语义输出合适的枚举
- 多肯定:多用肯定句,告诉大模型要做什么,不是限制大模型不做什么
- 结合功能:要结合功能流程设计prompt,不能期望一次与大模型的交互解决一切问题
# 应用
# 大模型能做什么
# 文本生成
- 广告文案
- 小说
- 分析报告
# 文本提炼
- 总结文章重点
- 用户需求提取
- 用户画像提取
- 建立内容提取
# 信息转换
- 代码生成
- 语言翻译
- 代码解释
# 大模型能不做什么
- 它不是搜索引擎。
- 他可以是搜索引擎的辅助
- 他不是数据库,没办办法记住读过的每一本书。
- 他可以和embedding技术结合
# 实际案例
- 代码提示、编写
- 通过微调将行业知识融入进入大模型,比如将骨科X光,可以做到从海量病例中快速给出检查结果,甚至拍片不再需要去医院,自助照相一样简单。
- 写小说,写小红书文案,写抖音视频录制脚本
# 本地知识库
langchain-chatchat (opens new window) (原名langchain-chatglm),一种利用 langchain (opens new window) 思想实现的基于本地知识库的问答应用,目标期望建立一套对中文场景与开源模型支持友好、可离线运行的知识库问答解决方案。支持多种大语言模型。
# 原理
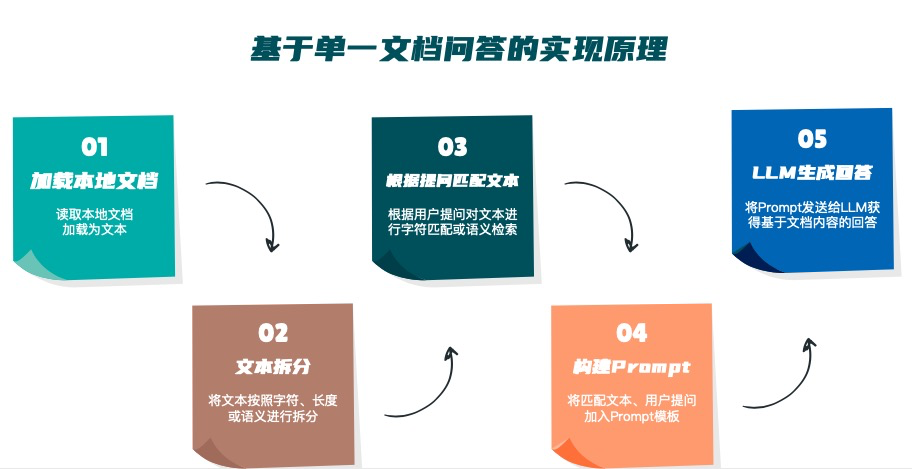
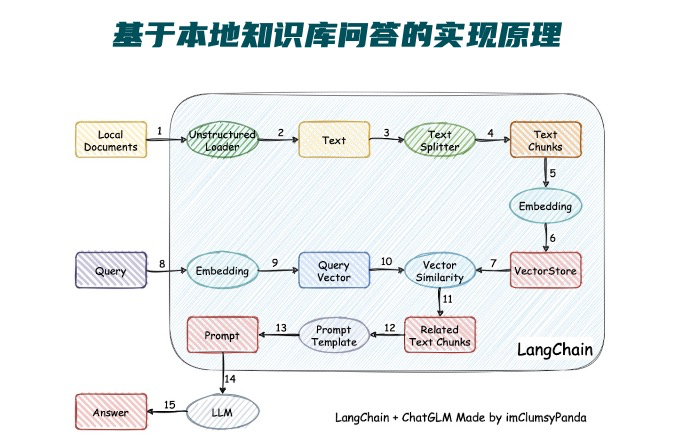
本项目实现原理如下图所示,过程包括加载文件 -> 读取文本 -> 文本分割 -> 文本向量化 -> 问句向量化 -> 在文本向量中匹配出与问句向量最相似的 top k个 -> 匹配出的文本作为上下文和问题一起添加到 prompt中 -> 提交给 LLM生成回答。
# langchain介绍
LangChain是一个开源库,旨在利用大型语言模型(LLM)的能力,并将它们与其他计算或知识源结合起来创建强大的应用程序。它是一种工具箱,为LLMs提供标准接口,并促进它们与其他工具的集成。
通过将LLMs与其他计算(例如执行复杂数学运算的能力)和知识库(例如提供实时库存)混合使用,LangChain可以使开发人员更容易地创建能够回答特定文档的问题、支持聊天机器人,以及创建决策制定代理等应用程序。
# Embedding
大模型的嵌入(Embedding)是指将高维度的数据(例如文本、图片、音频)映射到低维度空间的过程。在自然语言处理(NLP)中,大模型的嵌入通常用于将单词、短语或句子等文本单位表示为实数向量。
大模型的嵌入是通过训练模型从数据中学习得到的。在NLP中,常用的嵌入方法是词嵌入(Word Embedding),它将单词映射到连续的向量空间中。词嵌入可以捕捉到单词之间的语义和语法关系,使得相似的单词在嵌入空间中距离较近。
大模型的嵌入可以通过不同的方法来获取,其中最常见的方法是使用预训练的嵌入模型,如Word2Vec、GloVe和BERT等。这些预训练模型在大规模的文本数据上进行训练,学习得到了丰富的语言知识和语义关系。通过使用这些预训练模型,可以将文本单位转换为具有语义信息的向量表示。
大模型的嵌入在NLP任务中具有广泛的应用,如文本分类、命名实体识别、情感分析、机器翻译等。通过将文本单位表示为嵌入向量,可以更好地捕捉到文本的语义信息,从而提高模型在这些任务上的性能。
以下是几个常用的嵌入模型:
- Word2Vec:Word2Vec是一种经典的词嵌入模型,它通过训练神经网络来学习单词的分布式表示。Word2Vec可以捕捉到单词之间的语义和语法关系,常用的训练算法有CBOW和Skip-gram。
- GloVe:GloVe(Global Vectors for Word Representation)是一种基于全局词频统计的词嵌入模型。它通过在全局语料库上计算单词之间的共现概率来学习单词的向量表示。GloVe可以捕捉到单词之间的语义关系和词汇的全局结构。
- FastText:FastText是一种基于子词的词嵌入模型,它将单词表示为其子词的平均向量。FastText可以处理未登录词(Out-of-Vocabulary)和词形变化等问题,并且在处理具有丰富词汇的语言时表现良好。
- BERT:BERT(Bidirectional Encoder Representations from Transformers)是一种基于Transformer模型的预训练语言模型。BERT通过在大规模文本数据上进行无监督训练,学习得到了丰富的语言知识和上下文相关的词嵌入。BERT在多个NLP任务上取得了显著的性能提升。
- ELMO:ELMO(Embeddings from Language Models)是一种基于双向LSTM的预训练语言模型。ELMO通过在大规模文本数据上进行训练,学习得到了上下文相关的词嵌入。ELMO的特点是可以根据上下文动态地生成词嵌入。
# 向量数据库介绍
向量数据库是专门用来存储和查询向量的数据库。这些向量通常来自于对文本、语音、图像、视频等的向量化处理。与传统数据库相比,向量数据库可以处理更多非结构化数据(比如图像和音频)。
它通常提供以下功能和特性:
- 高效的向量存储:向量数据库使用高效的数据结构和索引技术来存储向量数据。这些技术可以有效地压缩和组织向量,以节省存储空间并提高查询性能。
- 快速的向量查询:向量数据库提供了针对向量数据的高效查询接口。它可以支持基于相似度的查询,例如根据欧氏距离或余弦相似度等度量来搜索最相似的向量。
- 索引和搜索技术:向量数据库使用各种索引和搜索技术来加速向量查询。例如,它可以使用基于树结构的索引(如KD树、球树)或哈希索引来组织和搜索向量数据。
- 扩展性和高可用性:向量数据库通常具有良好的扩展性和高可用性。它可以支持水平扩展,以处理大规模的向量数据集,并提供冗余和故障恢复机制,以确保数据的可靠性和可用性。
- 支持多种数据类型和操作:除了向量数据,向量数据库通常还支持其他数据类型和操作,如标量数据、文本数据和复杂查询操作。这使得它可以适用于各种应用场景和数据处理需求。
向量数据库在许多领域中都有广泛的应用,包括图像搜索、推荐系统、自然语言处理、生物信息学等。它们提供了一种高效和灵活的方式来存储和查询大规模的向量数据,为各种数据驱动的应用提供了强大的支持。
以下是三个常用的向量数据库:
- Milvus:Milvus是一个开源的向量数据库,专门用于存储和查询大规模向量数据。它支持高维向量的存储和快速相似度搜索,并提供了多种索引和搜索算法,如IVF、HNSW等。Milvus具有良好的扩展性和高可用性,并提供了Python、Java、Go等多种语言的客户端SDK。
- Faiss:Faiss是Facebook AI Research开发的一个高性能向量索引库。它提供了多种索引结构和搜索算法,如IVF、PQ等,以支持高效的向量存储和查询。Faiss具有出色的性能和可扩展性,并提供了C++和Python等语言的接口。
- Annoy:Annoy是一个快速的近似最近邻搜索库,用于高维向量的存储和查询。它使用了一种基于树的索引结构,可以在大规模向量数据集上进行高效的相似度搜索。Annoy支持多种编程语言,如Python、C++、Java等。
# 实战
项目地址:https://github.com/chatchat-space/Langchain-Chatchat.git
项目搭建参考langchain-chatglm搭建 (opens new window)
# 应用
- 打造专属私人助理、客服机器人
# AI绘画
# AI绘画简介
以为图片生成领域来说,最近几年有四大主流生成模型:生成对抗模型(GAN)、变分自动编码器(VAE)、流模型(Flow based Model)、扩散模型(Diffusion Model)等,基本主要都是基于深度学习为训练方式的模型。从2022年开始,主要爆火的图片生成模型是Diffusion Model(扩散模型)为主
目前适用人数比较多的是Stable Diffusion、MidJourney。
# Stable Diffusion
Stable Diffusion 算法上来自 “潜在扩散模型 (opens new window)”(LDM / Latent Diffusion Model),这个模型又是基于 2015 年提出的扩散模型(DM / Diffusion Model)。参考论文中介绍算法核心逻辑的插图,Stable Diffusion 的数据会在像素空间(Pixel Space)、潜在空间(Latent Space)、条件(Conditioning)三部分之间流转,其算法逻辑大概分这几步:
- 图像编码器将图像从像素空间(Pixel Space)压缩到更小维度的潜在空间(Latent Space),捕捉图像更本质的信息;
- 对潜在空间中的图片添加噪声,进行扩散过程(Diffusion Process);
- 通过 CLIP 文本编码器将输入的描述语转换为去噪过程的条件(Conditioning);
- 基于一些条件对图像进行去噪(Denoising)以获得生成图片的潜在表示,去噪步骤可以灵活地以文本、图像和其他形式为条件(以文本为条件即 text2img、以图像为条件即 img2img);
- 图像解码器通过将图像从潜在空间转换回像素空间来生成最终图像。
# 实战
项目地址:https://github.com/AUTOMATIC1111/stable-diffusion-webui.git
项目搭建参考stable-diffusion 使用 (opens new window)
# 模型下载
点击进入 https://civitai.com/ ,下载【majicMIX realistic】,使用默认模型也可以,不过想要生成某个特点的图片还是要找对应的模型。majicMIX realistic以写实为主。
# 参数配置
# demo
Prompt,生成图片的条件,或者说想要生成什么样的图片
1 girl a 24 y o woman, blonde, dark theme, soothing tones, muted colors, high contrast, look at at viewer, contrasty , vibrant , intense, stunning, captured in the late afternoon sunlight, using a Canon EOS R6 and a 16-35mm to capture every detail and angle, with emphasis on the lighting and shadows, late afternoon sunlight, 8K
Negative prompt ,反向提示词,不想生成什么样的图片,一般用于阻止生成畸形或血腥场面
(deformed, distorted, disfigured, doll:1.3), poorly drawn, bad anatomy, wrong anatomy, extra limb, missing limb, floating limbs, (mutated hands and fingers:1.4), disconnected limbs, mutation, mutated, ugly, disgusting, blurry, amputation, 3d, illustration, cartoon, flat , dull , soft, (deformed, distorted, disfigured:1.3), poorly drawn, bad anatomy, wrong anatomy, extra limb, missing limb, floating limbs,
其他参数
咒语词典,以上是普通使用,prompt还有权重,组合等特性
- http://tag.zoos.life/
- https://tags.novelai.dev/
使用chatgpt写提示词
# Stable Diffusion prompt 助理
你来充当一位有艺术气息的Stable Diffusion prompt 助理。
## 任务
我用自然语言告诉你要生成的prompt的主题,你的任务是根据这个主题想象一幅完整的画面,然后转化成一份详细的、高质量的prompt,让Stable Diffusion可以生成高质量的图像。
## 背景介绍
Stable Diffusion是一款利用深度学习的文生图模型,支持通过使用 prompt 来产生新的图像,描述要包含或省略的元素。
## prompt 概念
- 完整的prompt包含“**Prompt:**”和"**Negative Prompt:**"两部分。
- prompt 用来描述图像,由普通常见的单词构成,使用英文半角","做为分隔符。
- negative prompt用来描述你不想在生成的图像中出现的内容。
- 以","分隔的每个单词或词组称为 tag。所以prompt和negative prompt是由系列由","分隔的tag组成的。
## () 和 [] 语法
调整关键字强度的等效方法是使用 () 和 []。 (keyword) 将tag的强度增加 1.1 倍,与 (keyword:1.1) 相同,最多可加三层。 [keyword] 将强度降低 0.9 倍,与 (keyword:0.9) 相同。
## Prompt 格式要求
下面我将说明 prompt 的生成步骤,这里的 prompt 可用于描述人物、风景、物体或抽象数字艺术图画。你可以根据需要添加合理的、但不少于5处的画面细节。
### 1. prompt 要求
- 你输出的 Stable Diffusion prompt 以“**Prompt:**”开头。
- prompt 内容包含画面主体、材质、附加细节、图像质量、艺术风格、色彩色调、灯光等部分,但你输出的 prompt 不能分段,例如类似"medium:"这样的分段描述是不需要的,也不能包含":"和"."。
- 画面主体:不简短的英文描述画面主体, 如 A girl in a garden,主体细节概括(主体可以是人、事、物、景)画面核心内容。这部分根据我每次给你的主题来生成。你可以添加更多主题相关的合理的细节。
- 对于人物主题,你必须描述人物的眼睛、鼻子、嘴唇,例如'beautiful detailed eyes,beautiful detailed lips,extremely detailed eyes and face,longeyelashes',以免Stable Diffusion随机生成变形的面部五官,这点非常重要。你还可以描述人物的外表、情绪、衣服、姿势、视角、动作、背景等。人物属性中,1girl表示一个女孩,2girls表示两个女孩。
- 材质:用来制作艺术品的材料。 例如:插图、油画、3D 渲染和摄影。 Medium 有很强的效果,因为一个关键字就可以极大地改变风格。
- 附加细节:画面场景细节,或人物细节,描述画面细节内容,让图像看起来更充实和合理。这部分是可选的,要注意画面的整体和谐,不能与主题冲突。
- 图像质量:这部分内容开头永远要加上“(best quality,4k,8k,highres,masterpiece:1.2),ultra-detailed,(realistic,photorealistic,photo-realistic:1.37)”, 这是高质量的标志。其它常用的提高质量的tag还有,你可以根据主题的需求添加:HDR,UHD,studio lighting,ultra-fine painting,sharp focus,physically-based rendering,extreme detail description,professional,vivid colors,bokeh。
- 艺术风格:这部分描述图像的风格。加入恰当的艺术风格,能提升生成的图像效果。常用的艺术风格例如:portraits,landscape,horror,anime,sci-fi,photography,concept artists等。
- 色彩色调:颜色,通过添加颜色来控制画面的整体颜色。
- 灯光:整体画面的光线效果。
### 2. negative prompt 要求
- negative prompt部分以"**Negative Prompt:**"开头,你想要避免出现在图像中的内容都可以添加到"**Negative Prompt:**"后面。
- 任何情况下,negative prompt都要包含这段内容:"nsfw,(low quality,normal quality,worst quality,jpeg artifacts),cropped,monochrome,lowres,low saturation,((watermark)),(white letters)"
- 如果是人物相关的主题,你的输出需要另加一段人物相关的 negative prompt,内容为:“skin spots,acnes,skin blemishes,age spot,mutated hands,mutated fingers,deformed,bad anatomy,disfigured,poorly drawn face,extra limb,ugly,poorly drawn hands,missing limb,floating limbs,disconnected limbs,out of focus,long neck,long body,extra fingers,fewer fingers,,(multi nipples),bad hands,signature,username,bad feet,blurry,bad body”。
### 3. 限制:
- tag 内容用英语单词或短语来描述,并不局限于我给你的单词。注意只能包含关键词或词组。
- 注意不要输出句子,不要有任何解释。
- tag数量限制40个以内,单词数量限制在60个以内。
- tag不要带引号("")。
- 使用英文半角","做分隔符。
- tag 按重要性从高到低的顺序排列。
- 我给你的主题可能是用中文描述,你给出的prompt和negative prompt只用英文。
我的第一个主题是: 一个美丽的中国女孩
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
# AI绘画网站
[1] https://creator.nolibox.com/
[2] https://openai.com/research/clip
# 应用
- 结合chatgpt,stablediffusion完成小说及配图。
# AI音频生成
本次是对声音克隆的学习。
# VITS
声学模型是声音合成系统的重要组成部分
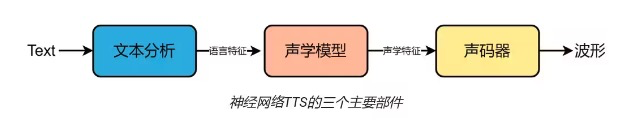
VITS(Variational Inference with adversarial learning for end-to-end Text-to-Speech)是一种语音合成方法,它使用预先训练好的语音编码器 (vocoder声码器) 将文本转化为语音。
VITS 的工作流程如下:
- 将文本输入 VITS 系统,系统会将文本转化为发音规则。
- 将发音规则输入预先训练好的语音编码器 (vocoder),vocoder 会根据发音规则生成语音信号的特征表示。
- 将语音信号的特征表示输入预先训练好的语音合成模型,语音合成模型会根据特征表示生成合成语音。
# 实战
项目地址: https://github.com/Plachtaa/VITS-fast-fine-tuning.git
用于声音克隆的项目与很多,大多需要准备高质量的人身数据,不能有伴奏或噪音,并且训练步骤复杂要求的算力也高,本次选择的VITS-fast-fine-tuning是一种低成本快速微调方式。
使用20段10秒内的音频即可训练出自己的声音模型,当前训练最快,数据要求最低的项目。
项目搭建参考模拟人声-文字生成语音 (opens new window)
# 应用
- 有声小说配音
- 将一个人的行为习惯,思维逻辑数据化,结合大模型进行微调,再模拟其的声线和音色,即可定制出数字人。
# 专业术语解释
# 训练微调
# 参数解释
epoch:表示将训练数据集中的所有样本都过一遍(且仅过一遍)的训练过程。在一个epoch中,训练算法会按照设定的顺序将所有样本输入模型进行前向传播、计算损失、反向传播和参数更新。一个epoch通常包含多个step。
batch:一般翻译为“批次”,表示一次性输入模型的一组样本。在神经网络的训练过程中,训练数据往往是很多的,比如几万条甚至几十万条——如果我们一次性将这上万条的数据全部放入模型,对计算机性能、神经网络模型学习能力等的要求太高了;那么就可以将训练数据划分为多个batch,并随后分批将每个batch的样本一起输入到模型中进行前向传播、损失计算、反向传播和参数更新。但要注意,一般batch这个词用的不多,多数情况大家都是只关注batch size的。
batch size:一般翻译为“批次大小”,表示训练过程中一次输入模型的一组样本的具体样本数量。前面提到了,我们在神经网络训练过程中,往往需要将训练数据划分为多个batch;而具体每一个batch有多少个样本,那么就是batch size指定的了。
step:一般翻译为“步骤”,表示在一个epoch中模型进行一次参数更新的操作。通俗地说,在神经网络训练过程中,每次完成对一个batch数据的训练,就是完成了一个step。很多情况下,step和iteration表示的是同样的含义。
iteration:一般翻译为“迭代”,多数情况下就表示在训练过程中经过一个step的操作。一个iteration包括了一个step中前向传播、损失计算、反向传播和参数更新的流程。当然,在某些情况下,step和iteration可能会有细微的区别——有时候iteration是指完成一次前向传播和反向传播的过程,而step是指通过优化算法对模型参数进行一次更新的操作。但是绝大多数情况下,我们就认为二者是一样的即可。
假设我们现在有一个训练数据集(这个数据集不包括测试集),其中数据的样本数量为1500。那么,我们将这1500条数据全部训练1次,就是一个epoch。其中,由于数据量较大(其实1500个样本在神经网络研究中肯定不算大,但是我们这里只是一个例子,大家理解即可),因此我们希望将其分为多个batch,分批加以训练;我们决定每1批训练100条数据,那么为了将这些数据全部训练完,就需要训练15批——在这里,batch size就是100,而batch就是15。而前面我们提到,每次完成对一个batch数据的训练,就是完成了一个step,那么step和iteration就也都是15。
# 举例
以上是我们对这一数据集加以1次训练(1个epoch)的情况,而一般情况下我们肯定是需要训练多次的,也就是多个epoch。我们假设我们需要训练3个epoch,相当于需要将这1500个样本训练3次。那么,step和iteration都会随着epoch的改变而发生改变——二者都变为45,因为15 * 3。但是,batch依然是15,因为其是在每一个epoch的视角内来看待的,和epoch的具体大小没有关系。
# 模型相关
# 模型参数具体是什么数据?
在机器学习中,**模型参数是模型内部用于描述数据的变量。**这些变量通常是在训练期间学习到的,以最小化模型预测与真实数据之间的误差。
具体来说,模型参数可以是权重、偏差或者其他可调整的变量。这些参数通过在训练数据上进行迭代来不断调整,以使模型更准确地预测新的数据。
例如,在神经网络中,模型参数是每个神经元的权重和偏差。在线性回归中,模型参数是回归系数和截距。在支持向量机中,模型参数是决策边界和支持向量。
这些模型参数可以用数值来表示,并且在训练过程中会不断调整以使模型更准确地预测新数据。在训练结束后,这些参数将用于进行预测,以便根据新数据的输入来生成相应的输出。
# 其中模型参数是变量数据还是常量数据?
在深度学习中,模型参数是变量数据,而不是常量数据。在模型训练过程中,模型参数的值是随着训练迭代而不断更新的,这些更新是通过计算损失函数梯度来实现的。因此,模型参数是在训练过程中不断变化的。在训练完成后,这些变量数据会被保存为模型的参数,供后续的推理或使用。但是,在推理或使用过程中,这些参数仍然可以被修改或更新,以适应不同的应用场景或任务。因此,模型参数是变量数据,而不是常量数据。
# 模型参数具体含有哪些数据?
在深度学习中,模型参数指的是神经网络中的权重和偏置,这些参数是用来定义模型的基本结构和特征表示能力的。
具体来说,模型参数包括两部分数据:权重和偏置。
- 权重(Weights):指的是神经网络中连接不同层之间的权重值,也称为连接权重(connection weights)。权重值是神经网络中非常重要的参数,决定了输入和输出之间的映射关系。在前向传播过程中,权重值被用来计算每个神经元的输出。在训练过程中,权重值是模型需要优化的参数之一。
- 偏置(Biases):指的是神经网络中每个神经元的偏置值,也称为偏移量(offset)。偏置值通常被添加到权重值乘以输入值的结果中,用来引入非线性变换。偏置值在训练过程中也是需要被优化的参数之一。
在深度学习中,模型参数的数量通常非常庞大,可能有数百万甚至数亿个参数,这也是深度学习需要大量数据和计算资源的原因之一。这些模型参数在训练过程中通过反向传播算法不断更新和优化,最终得到的模型参数可以用来进行预测、分类、生成等任务。
# 参考
- [1] 什么是AIGC、GPT、大模型 (opens new window)
- [2] 大模型应用领域 (opens new window)
- [3] 发展阶段及技术应用 (opens new window)
- [4] 基础模型与指令模型 (opens new window)
- [5] 大型语言模型实用指南 (opens new window)
- [6] 预训练 (opens new window)
- [7] 多机多卡训练 (opens new window)
- [8] 微调方式 (opens new window)
- [9] GPT-4大模型硬核解读,看完成半个专家 (opens new window)
- [10] stable diffusion 原理 (opens new window)
- [11] 如何写出好的提示词(stable diffusion) (opens new window)
- [12] 模型数据与参数解释 (opens new window)
