
CUDA和PyTorch关系-转载
CUDA
CUDA(Compute Unified Device Architecture)是由NVIDIA开发的用于并行计算的平台和编程模型。CUDA旨在利用NVIDIA GPU(图形处理单元)的强大计算能力来加速各种科学计算、数值模拟和深度学习任务。
GPU并行计算:
CUDA使GPU能够执行并行计算任务,从而大幅提高了计算性能。GPU由许多小型处理单元组成,每个处理单元都能够执行多个线程,这意味着GPU可以同时处理大量的计算任务。
CUDA编程模型:
CUDA提供了一种编程模型,允许开发人员编写C/C++代码,利用GPU的并行性来执行任务。开发人员可以编写称为"核函数"(kernel)的代码,这些核函数在GPU上并行执行。CUDA编程模型还提供了一组API(应用程序接口)来管理GPU内存、控制GPU设备和调度核函数的执行。
并行计算应用:
CUDA广泛用于各种领域的科学计算和高性能计算应用,包括:
- 数值模拟:CUDA可用于模拟物理现象、天气模型、流体力学等领域的数值模拟。
- 深度学习:深度学习框架如TensorFlow和PyTorch都支持CUDA,可用于训练和推理深度神经网络,加速图像识别、自然语言处理等任务。
- 分子动力学:用于模拟分子之间相互作用,有助于药物设计和材料科学研究。
- 地球科学:用于地震模拟、气象学、地球物理学等领域的大规模数值模拟。
NVIDIA GPU支持:
CUDA仅适用于NVIDIA GPU。不同版本的CUDA通常与特定型号的NVIDIA GPU兼容,因此需要确保你的GPU支持所选版本的CUDA。
CUDA工具和库:
NVIDIA提供了一套用于CUDA开发的工具和库,包括CUDA Toolkit、cuDNN(CUDA深度神经网络库)、cuBLAS(CUDA基础线性代数库)等。这些工具和库简化了CUDA应用程序的开发和优化过程。
Cudnn
cuDNN(CUDA Deep Neural Network Library)是由NVIDIA开发的用于深度学习的加速库。cuDNN旨在优化神经网络的前向传播和反向传播过程,以利用NVIDIA GPU的并行计算能力,从而加速深度学习模型的训练和推理。
深度学习加速:
cuDNN是专门为深度学习任务而设计的,旨在加速神经网络的训练和推理。它提供了一系列高度优化的算法和函数,用于执行神经网络层的前向传播、反向传播和权重更新。
GPU加速:
cuDNN充分利用NVIDIA GPU的并行计算能力,以高效地执行深度学习操作。这使得训练深度神经网络更快速,尤其是对于大型模型和大规模数据集。
深度学习框架支持:
cuDNN被广泛用于多个深度学习框架,包括TensorFlow、PyTorch、Caffe、MXNet等。这些框架通过cuDNN来加速模型的训练和推理过程,使得深度学习研究和开发更加高效。
提高性能:
cuDNN通过使用高度优化的卷积和池化算法、自动混合精度计算、内存管理和多GPU支持等技术,显著提高了深度学习任务的性能。这些优化可以加速卷积神经网络(CNN)、循环神经网络(RNN)、生成对抗网络(GAN)等各种类型的神经网络。
版本兼容性:
cuDNN的不同版本与NVIDIA GPU架构和深度学习框架的版本兼容。因此,为了获得最佳性能,你需要选择适用于你的GPU型号和深度学习框架版本的cuDNN版本。
免费使用:
cuDNN是免费的,可以在NVIDIA的官方网站上下载和使用。
PyTorch
PyTorch 是一个开源的深度学习框架,由Facebook的人工智能研究团队开发和维护。它是一个非常流行的深度学习框架,用于构建和训练神经网络模型。
动态计算图:
PyTorch 采用动态计算图(Dynamic Computational Graph)的方式来定义和执行神经网络。这意味着你可以像编写常规Python代码一样编写神经网络,同时保留了计算图的优势,使模型的构建和调试更加直观和灵活。
灵活性:
PyTorch 提供了丰富的张量操作,以及各种优化工具和模块,可以轻松构建各种类型的深度学习模型,包括卷积神经网络(CNN)、循环神经网络(RNN)、生成对抗网络(GAN)等。它还支持自定义神经网络层和损失函数,允许你创建高度定制的模型。
GPU加速:
PyTorch天然支持GPU加速,你可以在GPU上训练和执行神经网络,大幅提高了计算性能。PyTorch的GPU张量操作与CPU张量操作非常相似,使得将计算从CPU迁移到GPU变得相对容易。
动态调试:
由于采用动态计算图,PyTorch允许你在模型构建和训练过程中轻松进行动态调试,检查梯度、查看中间变量等。这对于理解和诊断模型行为非常有帮助。
丰富的生态系统:
PyTorch拥有庞大的用户社区,有许多开源项目、库和工具,可以扩展其功能。这些包括模型部署工具、迁移学习库、自然语言处理工具和计算机视觉工具,以及与其他深度学习框架的集成。
深度学习研究和教育:
PyTorch在深度学习研究和教育中非常流行,因为它易于学习、易于使用,并提供了丰富的教程和文档资源。它还被许多大学和研究机构用于深度学习课程和研究项目。
跨平台支持:
PyTorch支持多种操作系统,包括Linux、macOS和Windows,以及多种编程语言接口,如Python、C++等。这使得它适用于各种应用场景。
三者关系
CUDA、cuDNN 和 PyTorch 是三个不同但相关的组件,它们之间存在一些依赖关系,特别是在使用 PyTorch 进行深度学习开发时。
- CUDA(Compute Unified Device Architecture):
- CUDA是GPU并行计算平台:CUDA 是由 NVIDIA 开发的用于并行计算的平台和编程模型。它允许开发人员利用 NVIDIA GPU 的强大计算能力来加速各种科学计算、数值模拟和深度学习任务。
- PyTorch依赖CUDA:PyTorch 使用 CUDA 来加速神经网络的训练和推理。在 PyTorch 中,张量(Tensor)可以在 CPU 或 GPU 上进行计算。如果你想在 GPU 上训练神经网络,你需要确保 CUDA 已经正确安装并配置。
- 版本兼容性:不同版本的 PyTorch 可能需要特定版本的 CUDA。你需要根据所使用的 PyTorch 版本来选择合适的 CUDA 版本,以确保兼容性。
- cuDNN(CUDA Deep Neural Network Library):
- cuDNN用于深度学习加速:cuDNN 是 NVIDIA 开发的专门用于深度学习的加速库。它提供了高度优化的卷积和其他深度神经网络层的操作,以提高深度学习模型的性能。
- PyTorch依赖cuDNN:PyTorch 使用 cuDNN 来执行深度学习操作,尤其是在卷积神经网络(CNN)中。cuDNN 提供了高性能的卷积操作,使 PyTorch 能够在 GPU 上高效地进行前向传播和反向传播。
- 版本兼容性:不同版本的 PyTorch 需要特定版本的 cuDNN。你需要确保所使用的 cuDNN 版本与 PyTorch 版本兼容。
- PyTorch:
- PyTorch是深度学习框架:PyTorch 是一个开源的深度学习框架,用于构建、训练和部署神经网络模型。它提供了张量操作、自动求导、优化器、损失函数等工具,使深度学习任务更加便捷。
- PyTorch依赖CUDA和cuDNN:PyTorch 可以在 CPU 或 GPU 上运行,但为了获得最佳性能,特别是在大规模深度学习任务中,你通常会将 PyTorch 配置为在 GPU 上运行。这就需要确保 CUDA 和 cuDNN 已正确安装和配置。
显卡驱动
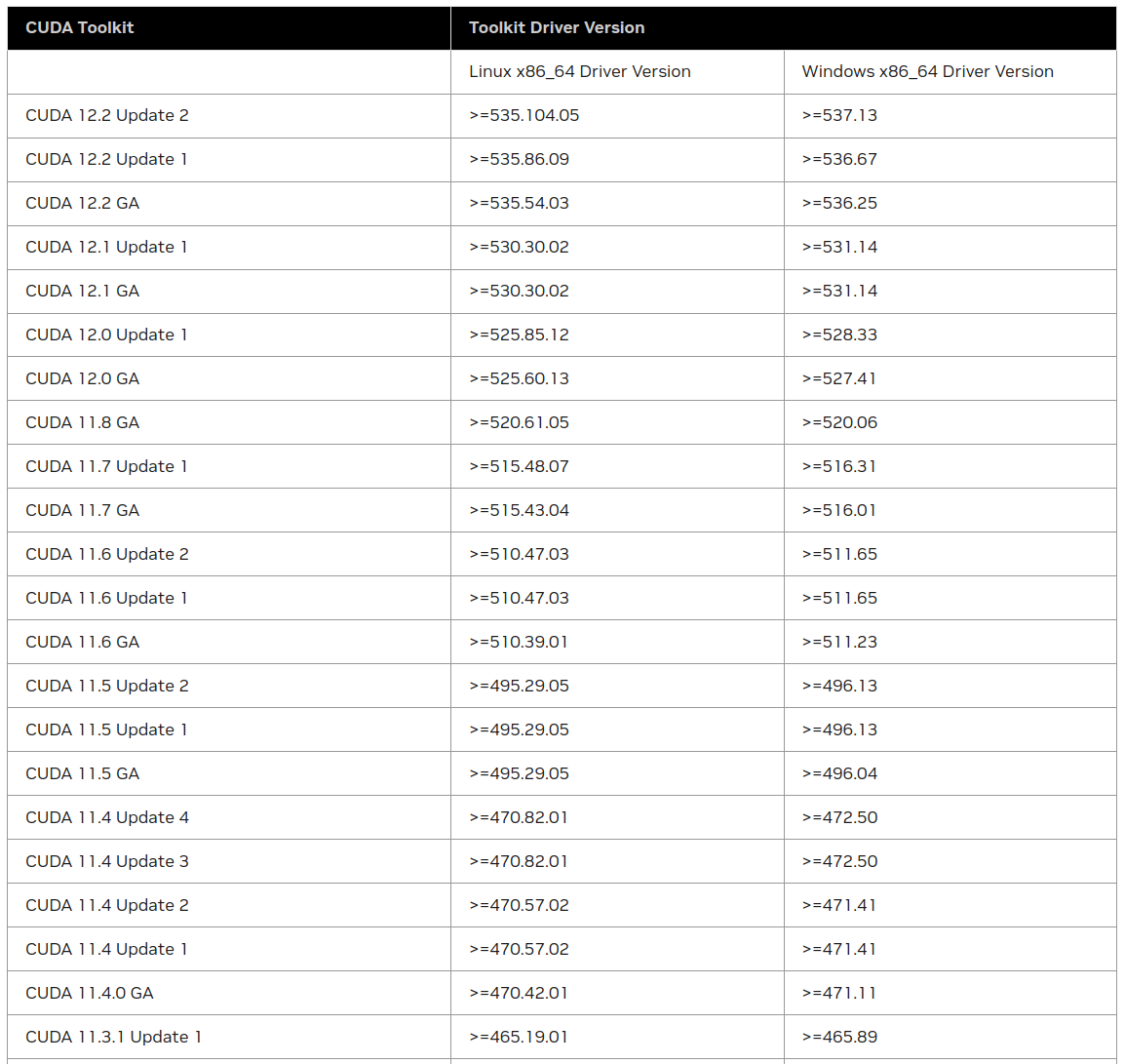
- CUDA Toolkit 包含显卡驱动:
- CUDA Toolkit 是一个由 NVIDIA 提供的开发工具包,其中包括了用于 CUDA 编程的库、编译器、工具和示例代码。而且,每个 CUDA Toolkit 版本都会附带特定版本的 NVIDIA 显卡驱动。
- 这意味着,如果你安装了特定版本的 CUDA Toolkit,它将包括与该版本兼容的 NVIDIA 显卡驱动。这个驱动版本是为了保证 CUDA 和 GPU 的正常运行,因此需要与 CUDA Toolkit 版本匹配。
- CUDA Toolkit和显卡驱动的兼容性:
- 不同版本的 CUDA Toolkit 需要与特定版本的显卡驱动兼容,以确保 GPU 正常工作。如果 CUDA Toolkit 和显卡驱动版本不匹配,可能会导致问题,例如 CUDA 不可用或运行时错误。
- 为了获得最佳性能和兼容性,你应该查看 NVIDIA 的官方文档,以了解哪个版本的 CUDA Toolkit 与哪个版本的显卡驱动兼容。通常,你可以在 NVIDIA 的官方网站上找到这些信息。
Pytorch版本

CUDA 和 PyTorch 之间存在版本依赖关系,这是因为 PyTorch 可以使用 CUDA 加速深度学习模型的训练和推理,需要与特定版本的 CUDA 兼容才能正常工作。以下是 CUDA 和 PyTorch 版本之间的关系:
- CUDA 和 PyTorch 的版本兼容性:
- 不同版本的 PyTorch 需要与特定版本的 CUDA 兼容,以确保能够利用 GPU 的计算能力。这是因为 PyTorch 使用 CUDA 来执行深度学习操作。
- 在使用 PyTorch 之前,你应该查看 PyTorch 官方文档或 GitHub 仓库中的文档,以了解当前版本所支持的 CUDA 版本。通常,PyTorch 的文档会明确说明支持的 CUDA 版本范围。
- 示例:
- 例如,如果你使用的是 PyTorch 1.8.0,官方文档可能会明确指出支持 CUDA 11.1,因此你需要安装 CUDA 11.1 或兼容版本的 CUDA 驱动来与 PyTorch 1.8.0 一起使用。
总结
确定 PyTorch、CUDA 和显卡驱动的版本并确保它们兼容,可以按照以下步骤进行:
确定显卡驱动版本:
首先,你需要确定你的计算机上安装了哪个版本的 NVIDIA 显卡驱动。你可以使用以下方法来查看:
- 在终端中执行
nvidia-smi命令。这个命令会显示当前系统上的 NVIDIA 显卡驱动版本以及相关信息。
- 在终端中执行
记下显示的 NVIDIA 驱动版本号。例如,版本号可能类似于 465.19.01。
确定 CUDA 版本:
通常,NVIDIA 显卡驱动与 CUDA 版本一起安装。所以,你可以通过查看 CUDA 的版本来确定。
在终端中执行以下命令来查看 CUDA 版本:
nvcc --version记下显示的 CUDA 版本号。例如,版本号可能类似于 11.1。
确定 PyTorch 版本:
使用以下 Python 代码来查看 PyTorch 的版本:
import torch print(torch.__version__)记下显示的 PyTorch 版本号。例如,版本号可能类似于 1.8.1。
检查兼容性:
一旦你确定了各个组件的版本号,你可以查阅 PyTorch 的官方文档,了解哪个版本的 PyTorch 与哪个版本的 CUDA 和显卡驱动兼容。通常,PyTorch 的文档会明确说明支持的 CUDA 版本范围。
如果你的 PyTorch 版本与你的 CUDA 版本和显卡驱动版本不兼容,你可能需要升级或降级其中一个或多个组件,以确保它们能够良好地协同工作。
往往我们在实际项目时,起始首先确定的是
PyTorch的版本,进而确定CUDA的版本,再根据CUDA的版本去查看自己平台的驱动是否支持。
